python识别带干扰线的验证码
python识别带干扰线的验证码,步骤肯定是首先去除干扰线,先分析干扰线与验证码的区别,比如干扰线比较细或颜色不一样,这里OpenCV是比较好用的,其次拆分验证码,拆成单个字符,然后对单个字符使用tensorflow进行训练,最后就可以根据训练模型识别验证码了。
下面是简单实现的步骤:
1. 准备一些原验证码图片并打好标记
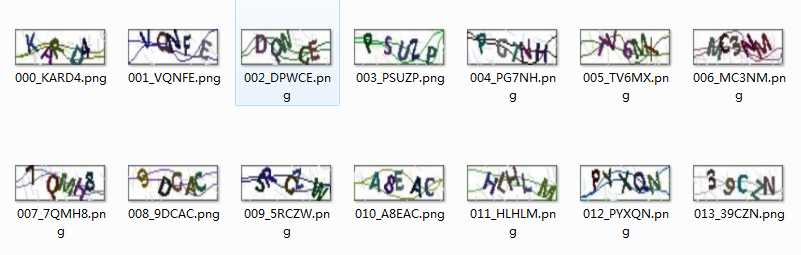
2. 去除干扰线
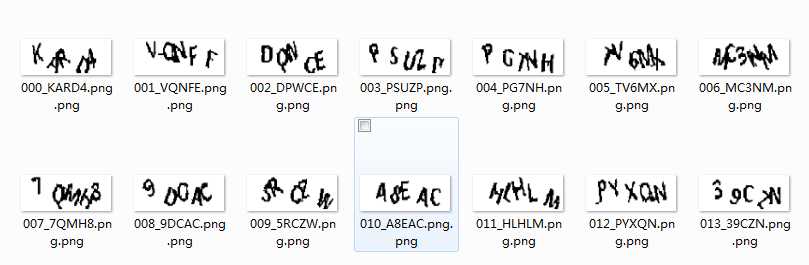
对于干扰线比较细的情况,可以直接使用OpenCV的腐蚀和膨胀函数去除干扰线。
例如
3. 拆分成单个字符,可以根据空白拆分,实在拆不开的直接平分即可

4. 将单个字符图片生成tfrecords
下面是简单实现的步骤:
1. 准备一些原验证码图片并打好标记
2. 去除干扰线
对于干扰线比较细的情况,可以直接使用OpenCV的腐蚀和膨胀函数去除干扰线。
例如
v = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 3), (-1, -1)) img = cv2.dilate(binary, v)去除后效果如下:
3. 拆分成单个字符,可以根据空白拆分,实在拆不开的直接平分即可
4. 将单个字符图片生成tfrecords
def _convert_dataset(split_name, filenames, dataset_dir):
assert split_name in ['train','tget_vcode_images']
with tf.Session() as sess:
output_filename = os.path.join(TFRECORD_DIR, split_name + '.tfrecords')
with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer:
for i, filename in enumerate(filenames):
try:
print('%s convert image %s, %s, %s' %(split_name, i+1, len(filenames), filename))
image_data = Image.open(filename)
image_data = image_data.resize((224, 224))
image_data = np.array(image_data.convert('L'))
image_data = image_data.tobytes()
labels = filename.split(".")[1][-1:]
num_labels = []
print(labels)
for j in range(1):
c = labels[j]
asv = ord(c.upper())
if asv >= 48 and asv <= 57:
k = ord(c)-ord('0')
elif asv >= 65 and asv <= 90:
k = ord(c)-ord('A')+10
else:
raise ValueError('No char')
num_labels.append(k)
#
example = image_to_tfexample(image_data, num_labels[0])
tfrecord_writer.write(example.SerializeToString())
except IOError as e:
print('can not read: ', filename)
5. 使用tensorflow训练模型x = tf.placeholder(tf.float32, [None, 224, 224])
y0 = tf.placeholder(tf.float32, [None])
lr = tf.Variable(0.003, dtype=tf.float32)
def read_and_decode(filename):
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'image': tf.FixedLenFeature([], tf.string),
'label0' : tf.FixedLenFeature([], tf.int64)
})
image = tf.decode_raw(features['image'], tf.uint8)
image = tf.reshape(image, [224, 224])
image = tf.cast(image, tf.float32) / 255.0
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
label0 = tf.cast(features['label0'], tf.int32)
return image, label0
image, label0 = read_and_decode(TFRECORD_FILE)
image_batch, label0_batch = tf.train.shuffle_batch(
[image, label0], batch_size=BATCH_SIZE,
capacity = 50000, min_after_dequeue = 10000, num_threads = 1)
train_network_fn = nets_factory.get_network_fn(
'alexnet_v2',
num_classes=CHAR_SET_LEN,
weight_decay=0.0005,
is_training=True)
with tf.Session() as sess:
X = tf.reshape(x, [BATCH_SIZE, 224, 224, 1])
#
logits0,end_points = train_network_fn(X)
#
one_hot_labels0 = tf.one_hot(indices=tf.cast(y0, tf.int32), depth=CHAR_SET_LEN)
#
loss0 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits0, labels=one_hot_labels0))
#
total_loss = loss0
#
optimizer = tf.train.AdamOptimizer(learning_rate=lr).minimize(total_loss)
#
correct_prediction0 = tf.equal(tf.argmax(one_hot_labels0,1), tf.argmax(logits0,1))
accuracy0 = tf.reduce_mean(tf.cast(correct_prediction0, tf.float32))
#
saver = tf.train.Saver()
#
sess.run(tf.global_variables_initializer())
#
coord = tf.train.Coordinator()
#
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
#
count = 0



